How to profile Datasets of Amorphic?

info
- Follow the steps mentioned below.
- Total time taken for this task: 20 Minutes.
- Pre-requisites: User registration is completed, logged in to Amorphic and role switched
Create Dataset with data profiling option
- Click on 'DATASETS' --> 'Datasets' from left navigation-bar.
- Click on ➕ icon at the top right corner.
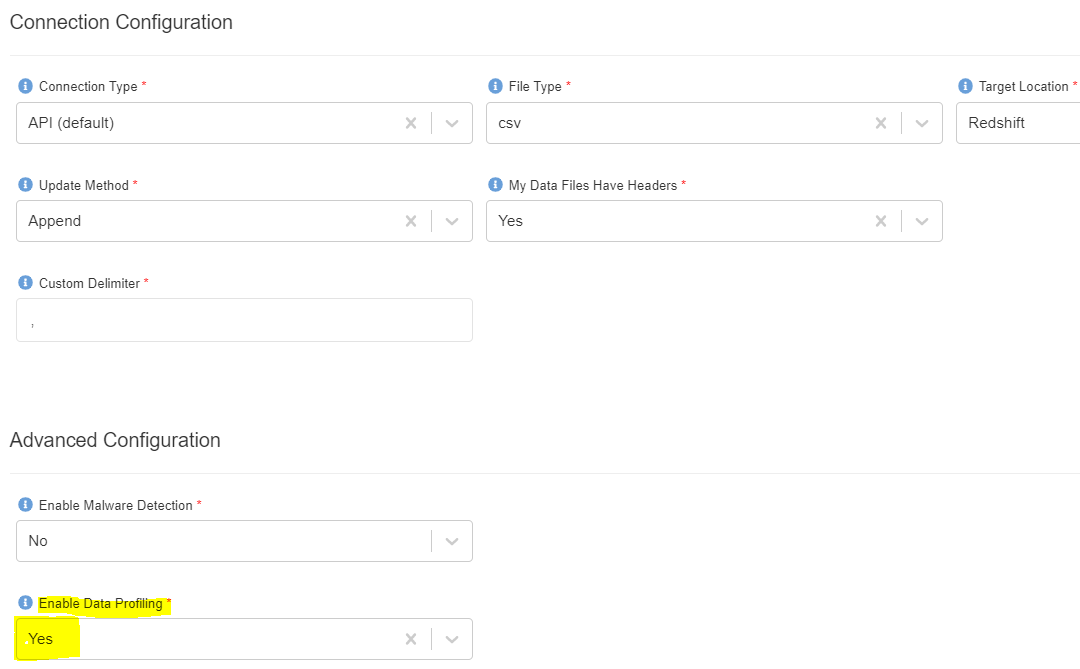
- Enter the following information.
{
"Dataset Name": "covid19_daily_us_profile_<your_userid>"
"Description": "Covid-19 daily report of US as of 5/31/2021. The target location is Redshift."
"Domain": "workshop(workshop)"
"Data Classifications":
"Keywords": "Retail"
"Connection Type": "API (default)"
"File Type": "csv"
"Target Location": "Redshift"
"Update Method": "Append"
"My Data Files Have Headers": "Yes"
"Custom Delimiter": ","
"Enable Malware Detection": "No"
"Enable Data Profiling": "Yes"
}
- Click on 'Register' button at the bottom to move to the next step.
- Click on the following CSV file to download it to your computer.
- Click on 'Click to upload' to upload the covid-19 csv file.
- Click on 'Extract Schema' as shown below.
- You will get a message 'File uploaded successfully'. Click OK.
- A new screen will appear with the schema extracted as shown below.
- Verify the columns and data types.
- Change the 'Sort Key Type' to None.
- Click on 'Publish Dataset'. You will get a 'completed the registration process successfully' message. Click OK.
- Click on 'Files' tab. Upload the same covid-19 csv file again.
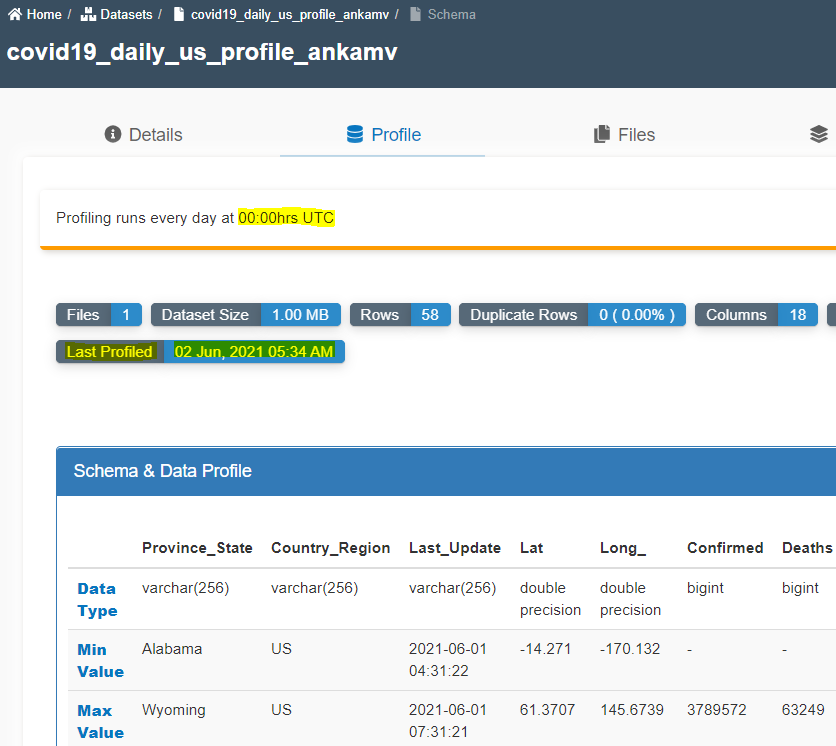
- Data profiling jobs run at 12 AM UTC everyday.
- Under the 'Profile' tab, you will see 'Schema & Data Profile'. If the data profiling option is disabled, you'd see 'Schema' only. Data profile is updated in this section as shown below.
Enable data profiling for existing datasets.
- You may enable data profiling for existing datasets with target as Redshift or S3Athena. S3 datasets cannot be profiled.
- Data profiling is enabled by clicking 'edit' ✏️ icon and change 'Enable Data Profiling' as 'Yes'.
tip
- How long does it take for all data profiles to get updated?
- Lets say there are 100 datasets to be profiled, and each dataset takes about 3 minutes (depends on the dataset size) for the data profile to be updated. With a concurrency factor of 5, the total time taken will be 20*3min = 60min.
- What happens in case of failures?
- In cases where a data profile fails to be extracted the error is displayed on the profile tab, and an email alert is sent to the subscribed user.